Dynamic Exploration Graph: Schnelle Suche in dynamischen Katalogen
Ein Deep Dive des vviinn Research Teams zum Dynamic Exploration Graph (DEG): dem graphbasierten Approximate-Nearest-Neighbor-Index (ANN), der Insertions, Deletions und Distribution Shifts im laufenden Betrieb bewältigt.


Search at Scale hat zwei zentrale Herausforderungen: die Qualität der Repräsentationen und die Geschwindigkeit, mit der sich die nächstgelegenen Treffer finden lassen. Sobald gute Embeddings vorhanden sind, braucht es immer noch einen Weg, Millionen von Vektoren mit interaktiver Latenz zu durchsuchen. Zwischen den Embeddings und den Ergebnissen liegt ein Index, und sein Design entscheidet, wie schnell ein bestimmtes Genauigkeitsniveau erreicht werden kann.
Die meisten Kataloge sind nicht statisch. Produkte kommen ständig hinzu und werden wieder entfernt. Beschreibungen, Bilder und die daraus abgeleiteten Embeddings verändern sich im Laufe der Zeit. Ein Index, der für einen festen Snapshot gebaut wurde, verliert an Qualität, sobald sich die Daten von diesem Ausgangszustand entfernen. Viele Systeme lösen das mit regelmäßigen vollständigen Rebuilds: geplante Downtime, zusätzlicher Engineering-Aufwand und eine abnehmende Suchqualität zwischen den Rebuild-Zyklen. Ausgerechnet in Phasen hoher Katalogaktivität ist die Suchqualität dann am schwächsten, also genau dann, wenn sie am wichtigsten ist.
Der Dynamic Exploration Graph (DEG) verfolgt einen anderen Ansatz. Er hält den Index strukturell stabil, während sich der Katalog verändert. Er unterstützt das Entfernen von Items bei garantierter Konnektivität und integriert neue Daten, ohne eine feste Verteilung vorauszusetzen. Gleichzeitig erreicht oder übertrifft er den Durchsatz statischer Indexe auf schwierigen, hochdimensionalen Daten.
Wie Approximate Nearest Neighbor Search funktioniert
Wenn ein Katalog aus einer Million Item-Embeddings besteht, bedeutet das Finden der ähnlichsten Treffer zu einer Query: die nächstgelegenen Vektoren in einem hochdimensionalen Raum zu finden. Mit steigender Dimensionalität wird ein vollständiges Durchsuchen des gesamten Katalogs schnell unpraktikabel. Approximate Nearest Neighbor Search (ANN) tauscht einen kleinen Verlust an Recall gegen einen großen Geschwindigkeitsgewinn ein. Die Ergebnisse sind damit sehr nah am exakten Resultat, aber nicht mathematisch garantiert exakt.
Graphbasierte ANN-Methoden bauen ein Netzwerk von Verbindungen zwischen Vektoren auf. Jeder Node ist mit seinen nächsten Nachbarn verbunden. Eine Suche startet an einem zufälligen Einstiegspunkt, folgt den Kanten in Richtung der Query und endet, wenn kein näherer Node mehr gefunden wird. Die Qualität dieser Verbindungen entscheidet direkt darüber, wie schnell ein hoher Recall erreicht werden kann. Das gilt unabhängig davon, was die Vektoren repräsentieren: Produktbilder, Textbeschreibungen oder jeden anderen Embedding-Typ.
Was der Benchmark zeigt
Die Grafik stammt aus Prof. Kai Uwe Barthels Tutorial Advanced Methods for Visual Information Retrieval and Exploration in Large Multimedia Collections, präsentiert auf der VISAPP 2026. Sie vergleicht den Exploration Graph (EG) und seine weiterentwickelte Variante, den continuous refining Exploration Graph (crEG), den direkten Vorgänger von DEG, mit HNSW und mehreren anderen etablierten Methoden auf drei Standard-Benchmarks: SIFT1M und Deep1M, die Bilddeskriptoren enthalten, sowie GloVe, das Word Embeddings enthält. Die Achsen zeigen Queries per Second (QPS) und Recall bei 100 Ergebnissen. Höher und weiter rechts ist besser.
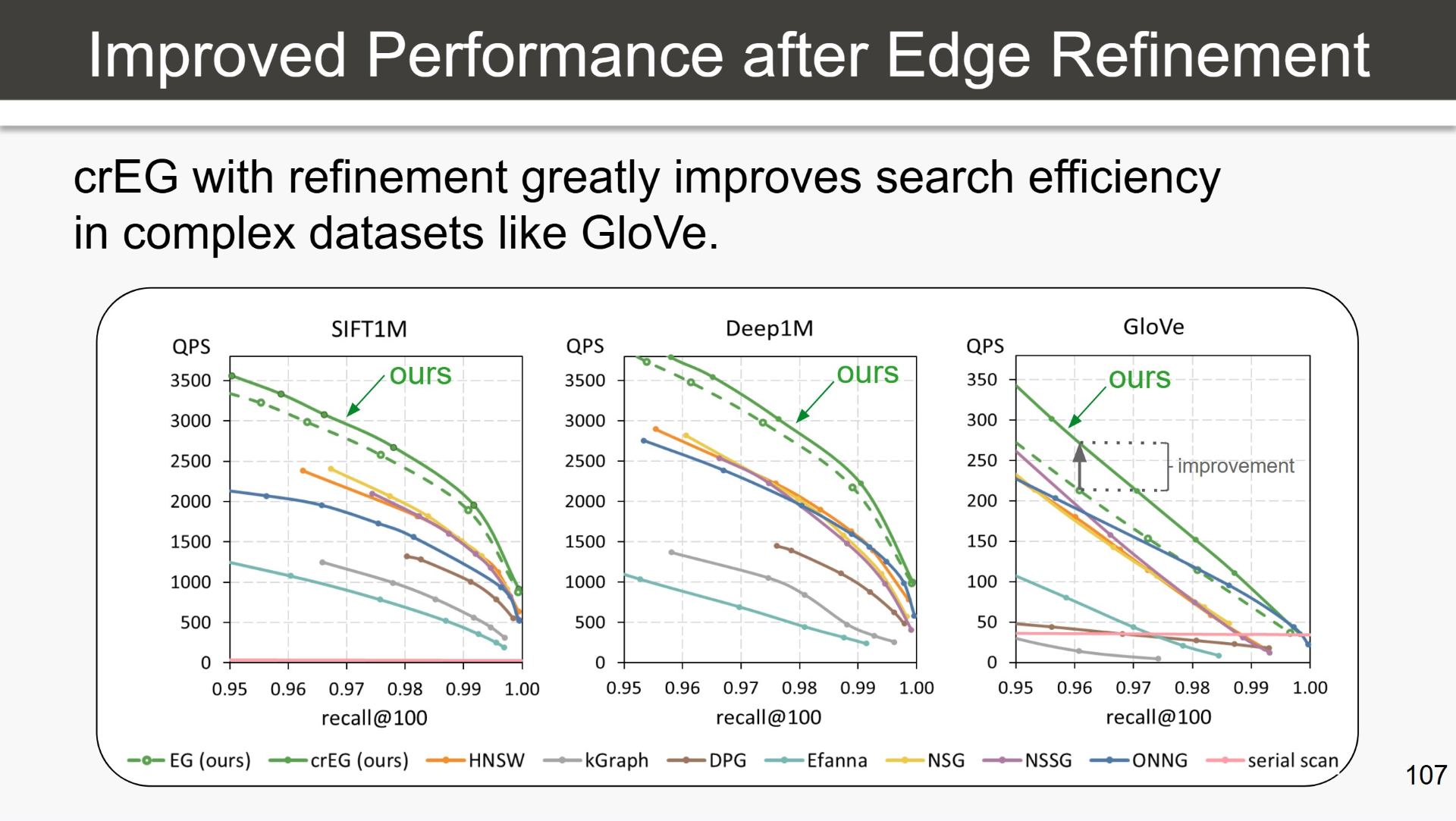
Auf SIFT1M und Deep1M liegt crEG bereits an der Spitze. HNSW, derzeit der am weitesten verbreitete ANN-Index in produktiven Systemen, liegt auf beiden Benchmarks über den gesamten Recall-Bereich hinweg klar unter crEG. Viele öffentliche ANN-Vergleiche hören an dieser Stelle auf. Das lässt viele Implementierungen besser aussehen, verschleiert aber, wie sich die Methoden auf schwierigeren Daten verhalten.
Bei GloVe werden die Unterschiede deutlich. Text-Embedding-Räume sind hochdimensional und deutlich weniger gleichmäßig verteilt. Dadurch sind sie erheblich schwieriger zu navigieren und zugleich repräsentativer für die Embedding-Räume, mit denen moderne Retrieval-Systeme tatsächlich arbeiten. Auf GloVe erreicht crEG bei hohem Recall (oberhalb von 0,99, also dort, wo produktive Retrieval-Systeme arbeiten) zwei- bis dreimal so viele Queries per Second wie HNSW und alle anderen Methoden im Vergleich. Auf Produktionsniveau übersetzt sich das direkt in niedrigere Infrastrukturkosten oder höheren Durchsatz bei gleichem Hardware-Budget.
Der dynamische Teil
Performance auf statischen Benchmarks ist die Grundvoraussetzung. crEG zeigt, dass der zugrunde liegende Graph-Ansatz schnell ist. DEG nimmt diese Grundlage und macht sie dynamisch. Die wichtigere Frage für den produktiven Einsatz lautet: Was passiert, wenn sich die Daten verändern?
Die meisten graphbasierten ANN-Indexe sind für einen festen Datensatz gebaut. Das Einfügen neuer Vektoren verschlechtert schrittweise die Graphqualität. Das Löschen von Vektoren wird entweder gar nicht unterstützt oder über Soft Deletion mit regelmäßiger Bereinigung gelöst. Wenn der Graph degradiert, sinkt der Recall – oder man kompensiert mit mehr Suchschritten, was den Durchsatz reduziert. Irgendwann bleibt nur der Rebuild.
DEG basiert auf zwei Garantien, die dieses Bild verändern:
Vertex deletion with guaranteed connectivity. Wenn ein Item entfernt wird, löscht DEG es sauber aus dem Graphen und verdrahtet die umliegende Struktur so neu, dass die Navigierbarkeit erhalten bleibt. Keine Ansammlung von Soft Deletes, keine Phantom Nodes, kein Recall Drift durch strukturelle Lücken.
Distribution agnostic insertion. Neue Vektoren werden integriert, ohne eine feste Verteilung vorauszusetzen. Der Graph passt sich an das an, was tatsächlich im Katalog vorhanden ist, nicht an das, was zum Zeitpunkt des initialen Builds vorhanden war. Der Index bleibt strukturell stabil, während sich der Katalog weiterentwickelt: Items kommen hinzu, Items werden entfernt, Embeddings werden neu trainiert. Ohne die Qualitätsverluste, die sich in statischen Indexen mit der Zeit ansammeln.
Die praktische Konsequenz: keine geplanten Rebuilds, keine Downtime rund um Produkt-Launches und keine Notwendigkeit, Infrastruktur auf Peak-Lasten während Index-Rebuilds auszulegen.
DEG im Einsatz
DEG ist als Open-Source-Python-Paket unter dem Namen deglib auf PyPI verfügbar und wird von der Visual Computing Group der HTW Berlin gepflegt. Das Paket bietet sowohl ein Python Interface als auch ein kompiliertes C++ Backend. Dadurch lässt es sich praktisch in bestehende ML-Pipelines integrieren, ohne Performance zu opfern. Eine Referenzimplementierung und weiterführende Dokumentation sind im DynamicExplorationGraph GitHub Repository von Visual Computing verfügbar.
Da vviinns Core für maximale Performance in Rust gebaut ist, treibt unsere eigene DEG-Implementierung jede einzelne Suche an. Unsere Kunden erhalten präzise, schnelle Ergebnisse; unabhängig davon, wann sie suchen: während eines großen Produkt-Launches, bei einem Mid-Season Refresh oder an einem ruhigen Dienstag. Und das, ohne dass wir Suchqualität und Verfügbarkeit um Index-Maintenance-Fenster herum planen müssen.
References
Hezel, N., Barthel, K. U., Schall, K., Jung, K. (2024). An Exploration Graph with Continuous Refinement for Efficient Multimedia Retrieval. ACM International Conference on Multimedia Retrieval (ICMR 2024).
Hezel, N., Barthel, K. U., Schilling, M., Schall, K., Jung, K. (2025). Dynamic Exploration Graph: A Novel Approach for Efficient Nearest Neighbor Search in Evolving Multimedia Datasets. International Conference on MultiMedia Modeling (MMM 2025).
Barthel, K. U. (2026). Advanced Methods for Visual Information Retrieval and Exploration in Large Multimedia Collections. Tutorial presented at VISAPP 2026 (International Conference on Computer Vision Theory and Applications).
Verwandte Beiträge

Warum Suche mehr benötigt als Content Understanding
