Dynamic Exploration Graph: Fast Search in Evolving Catalogs
A deep dive from the vviinn research team into Dynamic Exploration Graph (DEG): the graph-based Approximate Nearest Neighbor (ANN) index that handles insertions, deletions, and distribution shifts in production.


Search at scale has two problems: the quality of the representations and the speed of finding the closest ones. Once you have good embeddings, you still need a way to search for millions of vectors at interactive latency. What sits between the embeddings and the results is an index, and the design of that index decides how fast you can reach a given level of accuracy.
Most catalogs are not static. Products arrive and are removed constantly. Descriptions, images, and embeddings derived from them change over time. An index built for a fixed snapshot degrades as the data diverges from what it was built on. Most systems manage this with periodic full rebuilds: planned downtime, engineering overhead, and degraded search quality between rebuild cycles. Search quality ends up lowest during periods of highest catalog activity, exactly when it matters most.
The Dynamic Exploration Graph (DEG) is a different approach. It keeps the index structurally sound as the catalog changes, supports item removal with guaranteed connectivity, and integrates new data without assuming a fixed distribution, while matching or exceeding the throughput of static indexes on hard, high dimensional data.
How approximate nearest neighbor search works
When you have a million item embeddings, finding the most similar ones to a query means finding the closest vectors in high dimensional space. As dimensionality increases, scanning the full catalog becomes prohibitive. Approximate nearest neighbor (ANN) search trades a small amount of recall for a large gain in speed, returning results that are very close to exact rather than provably exact.
Graph-based ANN methods build a network of connections between vectors. Each node connects to its nearest neighbors. A search starts at a random entry point, follows edges toward the query, and terminates when it can no longer find a closer node. The quality of those connections directly determines how fast you can reach high recall, and this holds regardless of what the vectors represent: product images, text descriptions, or any other embedding type.
What the benchmark shows
The chart is drawn from Prof. Kai Uwe Barthel’s tutorial Advanced Methods for Visual Information Retrieval and Exploration in Large Multimedia Collections, presented at VISAPP 2026. It compares the Exploration Graph (EG) and its refined variant the continuous refining Exploration Graph (crEG), DEG’s direct predecessor, against HNSW and several other established methods on three standard benchmarks: SIFT1M and Deep1M, which contain image descriptors, and GloVe, which contains word embeddings. The axes are queries per second (QPS) and recall at 100 results. Higher and further right is better.
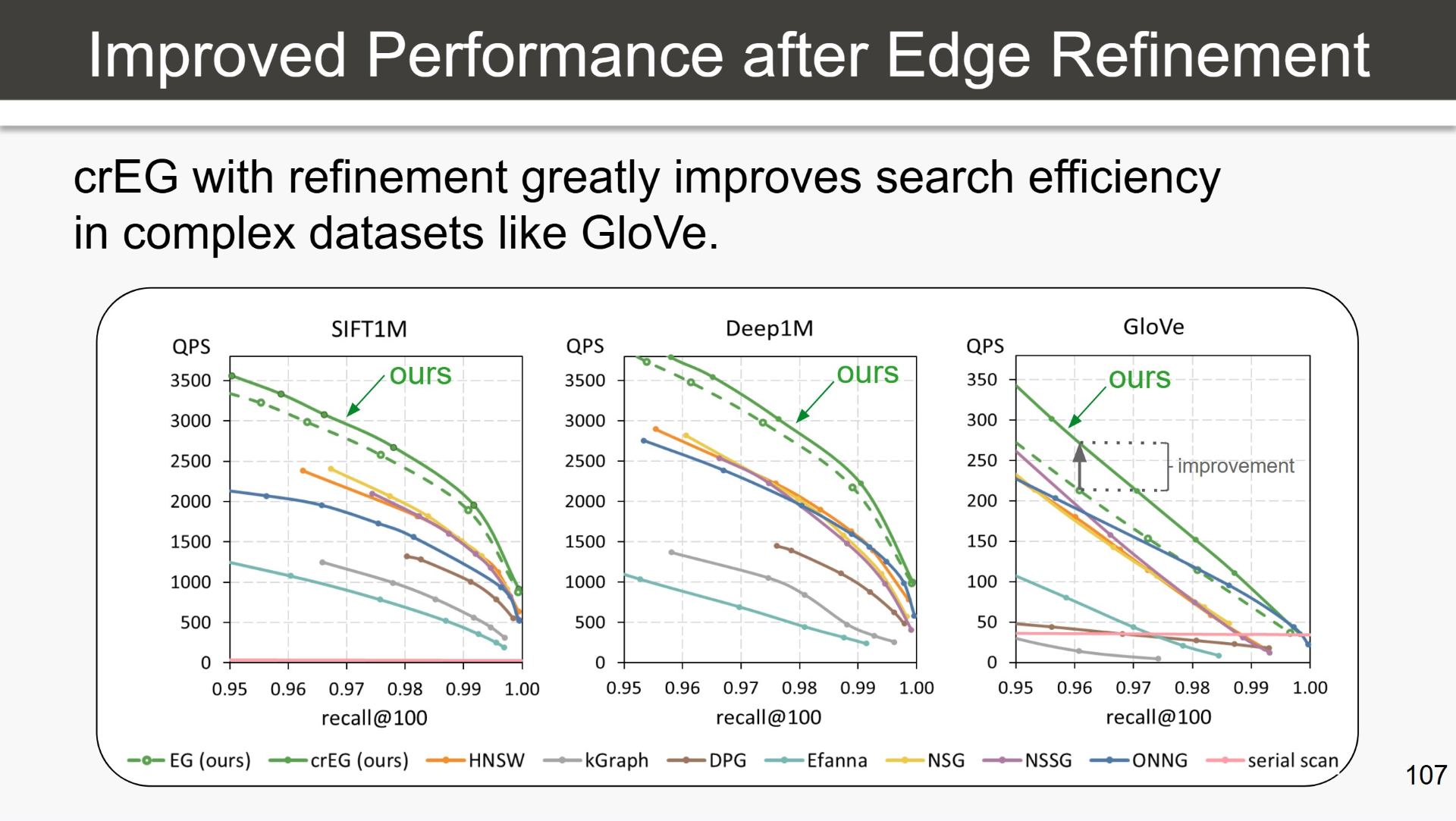
On SIFT1M and Deep1M, crEG already leads the field. HNSW, currently the most widely deployed ANN index in production systems, sits clearly below crEG across the full recall range on both benchmarks. Most public ANN comparisons stop here, which flatters many implementations and obscures how methods behave on harder data.
GloVe is where the differences become stark. Text embedding spaces are high dimensional and far less uniformly distributed, making them significantly harder to navigate and more representative of the embedding spaces modern retrieval systems actually encounter. On GloVe at high recall (above 0.99, where production retrieval operates), crEG achieves two to three times the queries per second of HNSW and every other method in the comparison. At production scale, that translates directly into lower infrastructure cost or higher throughput at the same hardware budget.
The dynamic part
Performance on static benchmarks is table stakes. crEG demonstrates that the underlying graph approach is fast. DEG takes that foundation and makes it dynamic. The more important question for production is what happens when the data changes.
Most graph-based ANN indexes are built for a fixed dataset. Inserting new vectors progressively degrades graph quality. Deleting vectors is either unsupported or handled by soft deletion with periodic cleanup. As the graph degrades, recall drops or you compensate with more search steps, reducing throughput. Eventually you rebuild.
DEG is built around two guarantees that change this picture:
Vertex deletion with guaranteed connectivity. When an item is removed, DEG removes it cleanly and rewires the surrounding graph to maintain navigability. No soft delete accumulation, no phantom nodes, no recall drift from structural holes.
Distribution agnostic insertion. New vectors are integrated without assuming a fixed distribution. The graph adapts to what is actually in the catalog, not to what was there at build time. The index stays structurally sound as the catalog evolves, items added, items removed, embeddings retrained, without the quality degradation that accumulates in static indexes over time.
The practical consequence: no scheduled rebuilds, no downtime around product launches, and no need to size infrastructure around peak rebuild load.
Using DEG
DEG is available as an open source Python package called deglib, published on PyPI and maintained by the Visual Computing group at HTW Berlin. The package provides both a Python interface and a compiled C++ backend, making it practical to integrate into existing ML pipelines without sacrificing performance. A reference implementation and further documentation are available in the DynamicExplorationGraph GitHub repository maintained by Visual Computing.
Since vviinn’s core is built with Rust for maximum performance, our own implementation of DEG powers every single search. Our customers get accurate, fast results regardless of when they search, during a major product launch, a mid-season refresh, or a quiet Tuesday, without us needing to plan around index maintenance windows.
References
Hezel, N., Barthel, K. U., Schall, K., Jung, K. (2024). An Exploration Graph with Continuous Refinement for Efficient Multimedia Retrieval. ACM International Conference on Multimedia Retrieval (ICMR 2024).
Hezel, N., Barthel, K. U., Schilling, M., Schall, K., Jung, K. (2025). Dynamic Exploration Graph: A Novel Approach for Efficient Nearest Neighbor Search in Evolving Multimedia Datasets. International Conference on MultiMedia Modeling (MMM 2025).
Barthel, K. U. (2026). Advanced Methods for Visual Information Retrieval and Exploration in Large Multimedia Collections. Tutorial presented at VISAPP 2026 (International Conference on Computer Vision Theory and Applications).
Related Posts

Enterprise AI Workers (Internal A2A): Meet Your New Automated Workforce
